

The Backend for Frontend (BFF) architecture pattern has been popular as a straightforward solution to enable calls to multiple microservices on a per client basis. BFFs came to the scene to speed up development by decoupling teams working on client-specific applications from other teams. Further, a BFF enables a specific view required for the client, allowing for a personalized and optimized response.
However, this pattern is rather troublesome to scale. This is because:
- Routing logic grows in complexity with each BFF/client added.
- There’s a lot of code duplication between the BFFs.
- A change in the backend requires multiple changes in the BFFs, which makes it challenging to make new features work or fix bugs.
So while BFFs are great for small apps as they can be set up pretty quickly, in an enterprise scenario they’re sure to result in a BFF sprawl.
This is where GraphQL federation makes all the difference. Replacing BFFs with a federated GraphQL API supported by tooling like Apollo results in great wins:
- Single source of truth for domain entities and backend service calls.
- Service call orchestration (query plans), observability, and operations metrics out of the box.
- Breaking change protection on client operations.
But how do you go about migrating from numerous BFFs to GraphQL federation?
In this tutorial, I’m going to demonstrate an incremental migration path that takes a demand-driven approach to GraphQL schema design.
What you’ll learn:
- How to quickly identify subgraph boundaries using event storming.
- How to leverage read models as a concept to determine client demand for data.
- How to iterate on the migration from BFFs to GraphQL federation feature by feature.
You can find all code examples used in the tutorial here.
Let’s dive in.
Part 1: Business domain discovery using event storming
Defining subgraph boundaries
Before we start the migration, we need to first get a sense of the future state we’ll be working towards. A federated GraphQL schema consists of a number of subgraphs. The subgraphs are essentially independent GraphQL APIs, exposing data from your microservices. The big questions are:
- How many subgraphs should we plan for?
- What data belongs to which subgraph?
This is where event storming comes in. This highly-effective, collaborative workshop technique rooted in domain-driven design was invented by Alberto Brandolini. In a nutshell, event storming consists in making business stakeholder knowledge visible on a board by organizing sticky notes (that represent business events) into business processes.
Event storming can be used to model a business from both a 10,000-foot view, as well as at a granular level. We’re going to start with the former, which is called a big picture event storm.
The first step is to identify all events that take place in our business. Assuming we’re doing this for an airline, the result could look something like this:

The next step is then organizing these domain events on a timeline according to what happens when:

Once we have a clear timeline, we need to identify some pivotal events. What we’re looking for are events that mark the transition from one “chapter” of this business narrative to another:

Having identified the pivotal events, we’re now able to define our domain boundaries, which means grouping the domain events into areas that are meaningful from a business perspective:

Since we arrived at 3 different domains, we can plan to have 3 subgraphs that are going to map one-to-one to each domain (roughly). This way, there will be no overlap between our subgraphs, as opposed to duplication in the BFFs.
Determining client demand for data
In order to figure out what data the clients require, we need to drill down at the use case level. We’re going to single out one use case from the Booking domain and create its process model using event storming.
For demonstration purposes, let’s assume we already modeled the booking use case. You can find a step by step guide on how this is done here.
Here’s what our process model looks like:

As you can see, the orange domain events have been supplemented by different colored stickies:
- Lavender stickies denote policies, i.e. sets of business rules.
- Green stickies represent read models which provide the information needed to make a decision.
- Blue stickies denote commands which represent actions that result in domain events.
What we’re most interested in right now are the read models. Notice how the read models logically line up with actual GraphQL queries:

There you have it! By modeling a specific use case, we arrived at the read models needed for this particular process, and consequently we were able to determine the client demand for data.
Part 2: Incremental migration path from BFFs to GraphQL federation
So far, we covered the use of event storming, including process modeling, for business domain discovery. Let’s now jump into the actual migration path.
Since we’re taking an incremental approach here, we’re going to single out one feature for the migration: flight check-in.
Step 1: Feature investigation for flight check-in
The first step is investigating the feature we want to migrate. In order to do that, we need go through a data demand discovery process that’s going to answer 4 questions:
- Which BFFs/clients are involved?
- What are views/screens involved?
- What are the user actions? (commands)
- What decision-making data do the users need? (read models)
Let’s map this out for the flight check-in feature:

We can see that the kiosk experience is a little bit different in that it has bag check-in, but other than that all 3 experiences require the same views, read models and commands.
We want to now focus on the read models, because they provide users with data needed to take action and, as we have seen in Part 1 of this tutorial, this is critical for our GraphQL schema.
Step 2: Dedupe read models
Previously, we pointed to the fact that there’s a lot of duplication between BFFs. This is exactly what happens with our flight check-in. Hence, we need to dedupe the decision-making data needed for our clients:

Step 3: Model the entities
Now that we have a definitive list of decision-making data for all 3 clients, we can proceed to modeling our entities.
In Apollo federation, entities are a fundamental concept that allow for multiple subgraphs to “federate” on different fields to the same type. This type spans across all subgraphs that use it and the combined shape of all subgraphs’ usage of that type is reflected in the supergraph.
In my experience, the most straightforward way to model entities is to first design the ideal client-side GraphQL queries to fulfill the requirements of the UI. GraphQL allows for this client-centric approach, as well as enables us to reduce the scope of work to one query at a time. Such a setup also lets us split up the work, because each query can be designed relatively independently of the rest of the system.
Remember, GraphQL is really about unlocking the clients’ ability to request the exact shape of data they need. Focusing on the ideal query that maps to a specific read model allows us to really understand the client demand for data, so that we can build a schema that can supply that demand. The idea is that we’re going to work our way from specific queries at a granular level to all possible types needed in the schema, and then combine these types to include all the different shapes of data required.
Let’s take a look at what this method looks like, step by step. First, we write a query that maps to the Fees read model:

Looking at the query, we can see the types that we’re going to need in the schema, so let’s list them:

We then rinse and repeat this process with the other read models:
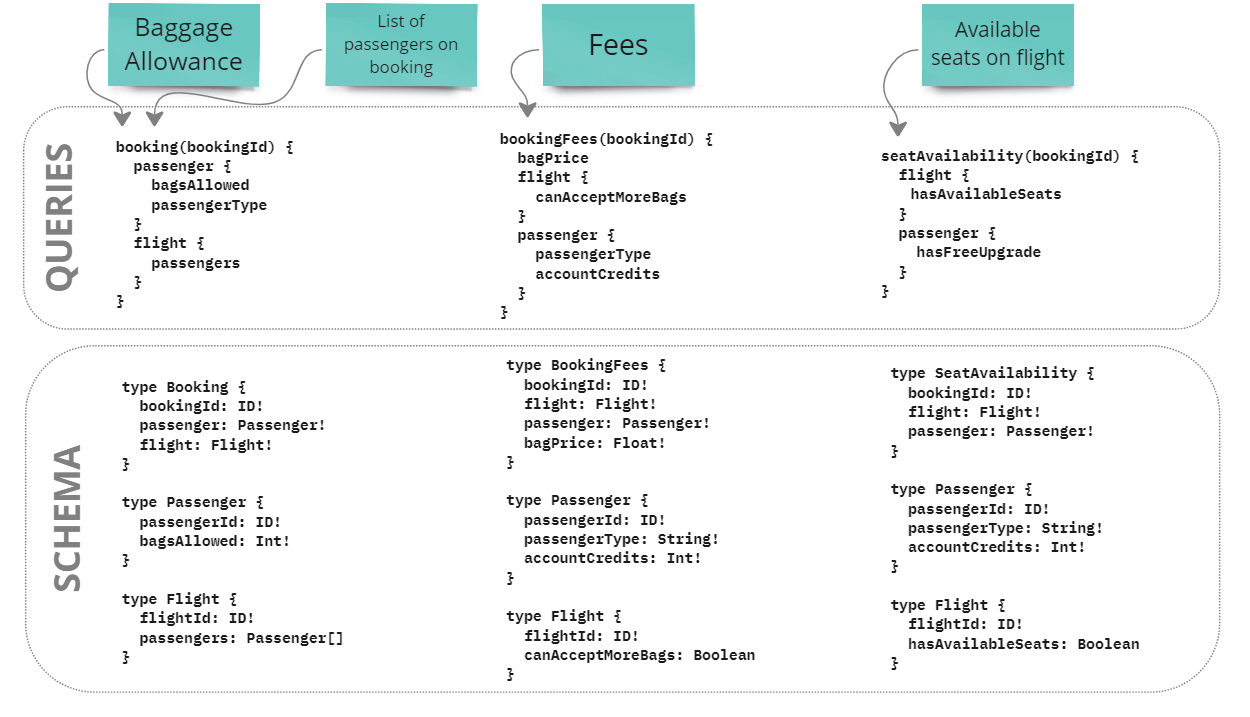
As you can see, we managed to work our way through a complex modeling process by breaking it up into small, repeatable tasks—designing queries that match the clients’ demand for data. This is something that’s accomplishable by a small team that’s decoupled from the rest of the ecosystem.
At this point, we begin to see common entities across the user experiences. Using the power of GraphQL federation, we can combine the fields on common entities into a “super entity” that will live in the supergraph, composed of a combination of all the shapes of that entity across subgraphs.
Let’s see what that looks like in case of the “Flight” entity:

Again, we rinse and repeat this process by combining all the fields from all similar types, which will give us the combined schema needed to fulfill client requests for the flight check-in feature:

Step 4: Federate the entities along domain boundaries
In part 1 of this tutorial, we covered how delineating the business domains is going to inform the design of our subgraphs. In the previous step, we arrived at the combined schema necessary to power the feature we are migrating. Now, we are ready to take the combined entities and map them to subgraphs!
The power of the GraphQL federation pattern lies in the fact that no matter how complex the additions to an entity are, there is a repeatable process of extracting out the application-specific logic needed to meet the new requirements.
This means that teams can deliver decoupled from one another and ship with confidence as long as their application adheres to the shapes defined in the supergraph schema. Remember, the supergraph schema is a contract between the frontend and backend teams. By adhering to the contract, both parties can work with a common understanding of the end goal, without being blocked by each other.
So how do we put this contract into effect? Our big picture event storm from earlier can show us the domain boundaries upon which we will define our subgraphs. The domain boundaries will reveal to us to which applications should serve the data we need.
In the case of the Flight entity, we can see that we need data from the Flight, Passenger, and Booking applications. Our supergraph schema changeset, i.e. the additional types/fields needed to satisfy the new UI requirements, informs us of the exact shape of data we need from the Application layer:

Now that our Application layer is ready to serve the data needed, we can move on to the Adaptor (API) layer where the subgraphs sit and where we implement the schema we designed earlier.
At Xolvio, we like to say that if you tidy up your domains, you’ll get your supergraph for free. What we mean by this is that if you apply domain-driven design principles to delineate your domain boundaries, and you use data demand discovery to design your schema, then authoring the subgraph itself is the easy part.
To build the subgraph we simply define the schema along the domain boundaries and connect the resolvers to our application layer so as to hydrate the queries we built.
On a side note, if your BFF and subgraph implementations turn out to be similar, you may be able to save some time by reusing data-fetchers. If that’s the case, a good rule of thumb is to try the following:
- Go back to the feature investigation results (step 1 of the migration path) to see which BFF has the greatest number of screens (i.e. requires the greatest number of read models).
- Attempt to to port the data-fetching logic from this most complex BFF into the corresponding subgraph resolvers.
Bear in mind though that each BFF migration will be unique, so some will be more suited for code reuse than others.
Back to our migration example: let’s see how our schema maps to subgraphs, and how those fields map to application calls. This is visualized by the following diagram:

We can move on by repeating this process for each type in the schema, until all application logic is built and all subgraphs have schema and resolvers added.
The final step is then migrating the clients to point to the federated GraphQL endpoint for the screens involved in the feature that we migrated.
And that’s it, we fully migrated the flight check-in feature from the BFFs to a federated GraphQL API and can now proceed to the next feature, repeating all of the above migration steps.
Final words
Migrating from a BFF architecture to GraphQL federation is a strategic move for organizations aiming to scale their systems while maintaining a clean, efficient, and easy-to-maintain codebase.
Following the migration path presented in this tutorial will allow you to make this move in an incremental, controlled fashion. Rome wasn’t built in a day, but migrating feature by feature is a tactic that can be realized by small teams working in parallel.
Once your migration is fully complete, you’ll be able to expose all data in the exact shape that the clients need, all from a single GraphQL endpoint. New shapes can be easily added, old shapes can be phased out by using the GraphQL @deprecated directive and common deprecation strategies.
No more duplicated BFF code to search through for each feature request. No more nasty bugs 6 layers deep when a backing service has an issue. GraphQL federation allows you to establish an extensible microservice architecture, enabling client teams and backend developers alike to progress independently, and reducing cross-org blockers to a minimum.
Let me know if you have any questions or thoughts in the comments below.




.jpg)